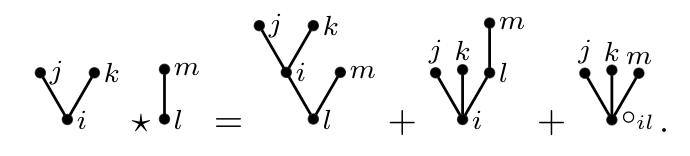
Policy Gradient Learning for Distributionally Robust Markov Decision Processes under Wasserstein Ambiguity
Published:
Recommended citation: https://arxiv.org/abs/2606.27610v1
Co-authors
Abstract
We study finite-horizon Markov Decision Processes (MDPs) under distributional uncertainty in the transition kernels and develop a policy-gradient framework for Wasserstein distributionally robust control. Ambiguity is modeled by state-action dependent Wasserstein balls around nominal transition kernels, leading to a max-min control problem over randomized policies and admissible transition laws. Since the worst-case transition law depends implicitly on the policy parameters, the usual policy-gradient argument does not apply. We address this difficulty by using a Wasserstein dual reformulation of the robust Bellman recursion and analyzing its directional differentiability. This yields an explicit recursive characterization of the robust policy gradient. Building on this characterization, we propose a robust actor-critic algorithm and illustrate its behavior on discrete and continuous benchmark examples.